

por Web Summit Río
StatusGator, que proporciona un servicio de gestión de sistemas, ha analizado si los fallos de Amazon Web Services (AWS) se concentran en una región concreta o si la tendencia cambia de año en año. StatusGator, que proporciona un servicio de administración de sistemas, utiliza datos agregados mediante el monitoreo continuo de la información pública en la página de estado oficial de AWS para organizar las fallas en 2025 desde una perspectiva tanto regional como de servicio.
La región de AWS menos confiable en 2025 | EstadoGator
https://statusgator.com/blog/aws-least-reliable-region-in-2025/
El análisis cubre el período comprendido entre el 1 de enero de 2025 y el 9 de diciembre de 2025 y se basa en las principales interrupciones anunciadas por AWS. El objetivo es una región comercial y se excluye GovCloud. EstadoGator esCorte masivo ocurrido en la región del norte de Virginia (us-east-1) el 20 de octubre de 2025«Fue una oportunidad para nosotros de reconsiderar nuestro análisis anterior», y además de comparar regiones, también estamos verificando el desglose de los servicios de AWS afectados.
En conclusión, StatusGator informa que «la región de AWS menos confiable en 2025 fue us-east-1». us-east-1 (Norte de Virginia) ocupó el primer lugar en términos de número de fallas, tiempo de inactividad acumulado y número de componentes afectados, con 10 fallas, interrupciones acumuladas de 33 horas y 49 minutos y 126 componentes afectados.
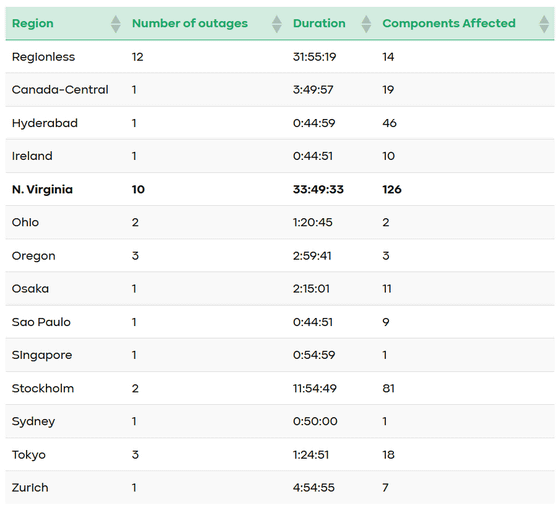
Además, StatusGator analizó que en 2025 hubo más fallas que no fueron atribuidas a una región específica que en años anteriores. Se produjeron un total de 12 fallas que no se atribuyeron a una región específica y la interrupción acumulada fue de aproximadamente 32 horas. Esto se explica como una indicación de la posibilidad de un aumento de fallas que abarquen múltiples regiones o sean altamente globales, en lugar de un problema de una sola región.
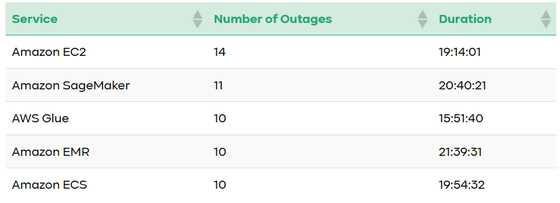
Además, cuando clasificamos las fallas no solo por región sino también por servicio, la computación en la nube, el análisis, la inteligencia artificial y el aprendizaje automático fueron los más destacados. Los servicios con una gran cantidad de fallas incluyen:Amazon EC2Hubo 14 casos,Amazon SageMaker11 casos,Pegamento AWS10 casos,EMR de Amazon10 casos,Amazon ECSseguido de 10 artículos. Entre los cinco servicios principales, Amazon EMR tuvo la interrupción acumulada más larga con 21 horas y 39 minutos. Además, SageMaker tiene más fallas de las esperadas para un servicio de aprendizaje automático y está llamando la atención como una nueva tendencia en términos de confiabilidad.
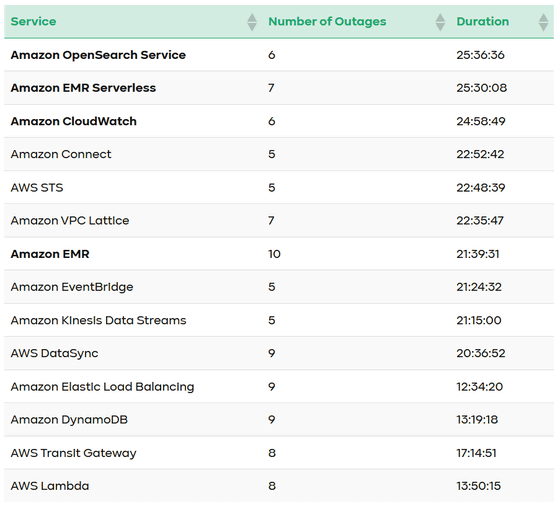
Por otro lado, además de los servicios con un gran número de casos, también se resumen los servicios que llevan mucho tiempo fuera de servicio o han tenido una gran repercusión. Para aquellos cuyo tiempo de inactividad acumulado exceda las 24 horas,Servicio de búsqueda abierta de Amazon、Amazon EMR sin servidor、Amazon CloudWatchAmbos se explican como efectos acumulativos durante un largo período de tiempo. ademásConexión de Amazony AWS STS,Red de Amazon VPCEl tiempo de inactividad acumulado también fue largo. Además, se han observado cortes de larga duración en servicios de gran importancia como base, yAmazonDynamoDB、AWS Lambda、Equilibrio de carga elástico de AmazonStatusGator explicó que era fácil vincular las fallas de la región y las fallas del servicio.
StatusGator está probando tres hipótesis sobre por qué el número de fallas en us-east-1 es tan alto.
En cuanto a la primera hipótesis, «US-East-1 se rompe fácilmente porque proporciona muchos servicios», puede ser un factor de complejidad, pero no se puede decir que sea la única causa fundamental.
En cuanto a la segunda hipótesis, «us-east-1 es antigua y tiene una estructura diferente», AWS no ha aportado ninguna prueba, y aunque los cortes en Tokio (ap-northeast-1) y Sydney (ap-southeast-2), que están incluidos en las regiones antiguas, son pequeños, StatusGator afirma que ni siquiera las cifras de 2025 están corroboradas, ya que se han producido cortes que duraron varias horas en regiones relativamente nuevas como Zurich (eu-central-2) y Hyderabad. (ap-sur-2).
StatusGator señala que, según datos de 2025, US-East-1 es monitoreado por más del doble de usuarios que Oregon (US-West-2) y más del triple de usuarios que otras regiones. Explicó que cuantos más clientes hay, más aumenta la carga, el estrés de las operaciones reales y, como resultado, es más probable que ocurran fallas de la escala anunciada. Concluye que la tercera hipótesis, «us-east-1 es la más utilizada y tiene una carga alta, por lo que hay muchas fallas», es la más probable.
Copie el título y la URL de este artículo.









{kind=link}