

En colaboración con OpenAI, NVIDIA ha optimizado los nuevos modelos GPT-ASS de código abierto de la compañía para las GPU NVIDIA, que ofrece una inferencia inteligente y rápida de la nube a la PC. Estos nuevos modelos de razonamiento permiten aplicaciones de AI de agente como búsqueda web, investigación en profundidad y muchos más.
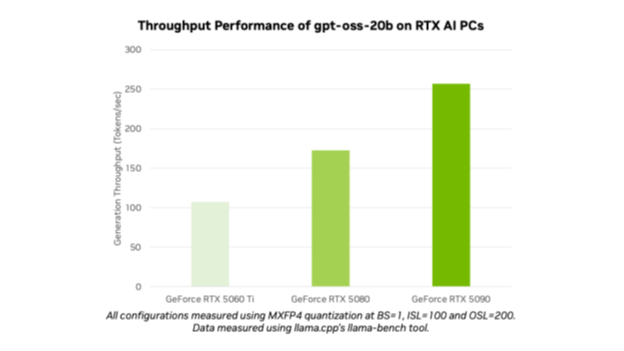
Con el lanzamiento de GPT-OSS-20B y GPT-OSS-20B, OpenAI ha abierto modelos de vanguardia a millones de usuarios. Los entusiastas y desarrolladores de la IA pueden usar los modelos optimizados en las PC y estaciones de trabajo NVIDIA RTX AI a través de herramientas y marcos populares como Ollama, Llama.CPP y Microsoft AI Foundry Local, y esperan un rendimiento de hasta 256 tokens por segundo en la GPU NVIDIA GEFORCE RTX 5090.
«Openai mostró al mundo lo que podría construirse en Nvidia AI, y ahora están avanzando la innovación en el software de código abierto», dijo Jensen Huang, fundador y CEO de NVIDIA. «Los modelos GPT-ASS permiten a los desarrolladores de todas partes construir sobre esa base de código abierto de última generación, fortaleciendo el liderazgo tecnológico estadounidense en IA, todo en la infraestructura de cálculo de IA más grande del mundo».
El lanzamiento de los modelos destaca el liderazgo de IA de NVIDIA desde la capacitación hasta la inferencia y de la nube a la PC AI.
Abierto para todos
Tanto GPT-OSS-20B como GPT-OSS-20B son modelos de razonamiento flexibles y de peso abierto con capacidades de cadena de pensamiento y niveles de esfuerzo de razonamiento ajustable utilizando la popular arquitectura de la mezcla de expertos. Los modelos están diseñados para admitir características como seguimiento de instrucciones y uso de herramientas, y fueron entrenados en GPU NVIDIA H100.
Estos modelos pueden admitir hasta 131,072 longitudes de contexto, entre los más largos disponibles en la inferencia local. Esto significa que los modelos pueden razonar a través de problemas de contexto, ideales para tareas como la búsqueda web, la asistencia de codificación, la comprensión del documento y la investigación en profundidad.
Los modelos OpenAI Open son los primeros modelos MXFP4 admitidos en NVIDIA RTX. MXFP4 permite una alta calidad del modelo, ofreciendo un rendimiento rápido y eficiente al tiempo que requiere menos recursos en comparación con otros tipos de precisión.
Ejecute los modelos Operai en Nvidia RTX con Ollama
La forma más fácil de probar estos modelos en PCS RTX AI, en GPU con al menos 24 GB de VRAM, es usar la nueva aplicación Ollama. Ollama es popular entre los entusiastas y desarrolladores de la IA por su facilidad de integración, y la nueva interfaz de usuario (UI) incluye soporte listo para usar para los modelos de peso abierto de OpenAI. Ollama está completamente optimizado para RTX, lo que lo hace ideal para los consumidores que buscan experimentar el poder de la IA personal en su PC o la estación de trabajo.
Una vez instalado, Ollama permite chatear rápido y fácil con los modelos. Simplemente seleccione el modelo en el menú desplegable y envíe un mensaje. Debido a que Ollama está optimizado para RTX, no hay configuraciones o comandos adicionales necesarios para garantizar el rendimiento superior en las GPU compatibles.
La nueva aplicación de Ollama incluye otras características nuevas, como soporte fácil para PDF o archivos de texto dentro de los chats, el soporte multimodal en los modelos aplicables para que los usuarios puedan incluir imágenes en sus indicaciones y longitudes de contexto fácilmente personalizables cuando trabajan con grandes documentos o chats.
Los desarrolladores también pueden usar Ollama a través de la interfaz de línea de comandos o el Kit de desarrollo de software de la aplicación (SDK) para alimentar sus aplicaciones y flujos de trabajo.
Otras formas de usar los nuevos modelos Operai en RTX
Los entusiastas y los desarrolladores también pueden probar los modelos GPT-OSS en PC RTX AI a través de varias otras aplicaciones y marcos, todos impulsados por RTX, en GPU que tienen al menos 16 GB de VRAM.
Nvidia continúa colaborando con la comunidad de código abierto en Llama.CPP y la Biblioteca Tensor GGML para optimizar el rendimiento en las GPU RTX. Las contribuciones recientes incluyen la implementación de gráficos CUDA para reducir los gastos generales y agregar algoritmos que reducen los gastos generales de la CPU. Echa un vistazo al repositorio de Llama.cpp GitHub para comenzar.
Los desarrolladores de Windows también pueden acceder a los nuevos modelos de Openai a través de Microsoft Ai Foundry Local, actualmente en Vista previa pública. Foundry Local es una solución de inferencia AI en el dispositivo que se integra en los flujos de trabajo a través de las interfaces de programación de la línea de comandos, SDK o de aplicaciones. Foundry Local usa el tiempo de ejecución de ONNX, optimizado a través de CUDA, con soporte para Nvidia Tensorrt para RTX próximamente. Comenzar es fácil: instale Foundry Local e invoque «Foundry Model Run GPT-OSS-20B» en una terminal.
El lanzamiento de estos modelos de código abierto inicia la próxima ola de innovación de IA de entusiastas y desarrolladores que buscan agregar razonamiento a sus aplicaciones de Windows aceleradas con IA.
Cada semana, el Garaje rtx ai La serie de blogs presenta innovaciones y contenido de IA impulsados por la comunidad para aquellos que buscan aprender más sobre los microservicios NIM NIM y los planos de IA, así como la construcción Agentes de IAflujos de trabajo creativos, aplicaciones de productividad y más sobre PC y estaciones de trabajo de IA.
Conectar a NVIDIA AI PC en Facebook, Instagram, Tiktok y incógnita – y manténgase informado suscribiéndose al Boletín RTX AI PC. Únete a Nvidia’s Servidor de discordia Para conectarse con los desarrolladores de la comunidad y los entusiastas de la IA para las discusiones sobre lo que es posible con RTX AI.
Sigue la estación de trabajo de Nvidia en LinkedIn y incógnita.
Ver aviso con respecto a la información del producto de software.









{kind=link}